
Detectar patrones es un núcleo importante en el mundo del Procesamiento del Lenguaje Natural (NLP). Esta detección de patrones nos permite clasificar documentos, lo que tiene muchas aplicaciones: análisis de sentimiento ↗ (sentiment analysis), recuperación de documentos ↗ (document retrieval), búsqueda web, filtrado de spam ↗, etc. Esta clasificación se hace de manera automática de forma supervisada o no supervisada (también conocida como clustering de documentos).
Entre las técnicas más clásicas y utilizadas (generalmente supervisadas) encontramos clasificadores Naive Bayes ↗, árboles de decisión ↗ (ID3 o C4.5), tf-idf ↗, Latent semantic indexing (LSI) ↗ y Support vector machines (SVM) ↗. Algunas técnicas utilizadas para extraer características suelen inspirarse en cómo el ser humano es capaz de aprender de información simple y llegar a información más compleja. Se pueden diferenciar entre redes neuronales ↗ (algunas topologías de redes neuronales se engloban dentro del concepto ‘deep learning ↗’) y técnicas que no usan estas redes ↗ para reconocer patrones.
El problema de la clasificación de documentos#
En BEEVA ↗ nos hemos encontrado varias veces con un mismo problema: ¿cómo sabemos si dos documentos son semejantes? (y con “semejantes” queremos decir que tratan de lo mismo). Esto, entre otras cosas, nos permitiría categorizar documentos dentro del mismo tema de manera automática. Así que, a priori, nos encontramos con dos retos:
- El primer reto es ser capaces de extraer esa semántica del texto de los documentos. Y es que entender un documento de manera automática nos permite clasificarlo, extraer de qué temas trata y aprender nuevos conceptos. Para esto necesitamos algo capaz de extraer este significado de manera eficiente.
- El segundo reto es intentar categorizar documentos de tal manera que de un documento podemos obtener palabras clave, de ahí sacar el tema y luego la categoría. De este reto hablaremos en un próximo artículo.
Reto: Extracción de semántica#
Necesitamos representar los documentos de manera que los algoritmos que usemos los puedan entender. Normalmente, estas representaciones o modelos están basadas en matrices de características que posee cada documento. Para representar textos, podemos usar técnicas de representación de manera local o de manera continua. La representación local es aquella en la que solo tenemos en cuenta las palabras de forma aislada y se representa como un conjunto de términos índice o palabras clave (n-gramas ↗, bag-of-words ↗…). Este tipo de representación no tiene en cuenta la relación entre términos. La representación continua es aquella en la que sí se tiene en cuenta el contexto de las palabras y la relación entre ellas y se representan como matrices, vectores, conjuntos e incluso nodos (LSA ↗ o LSI ↗, LDS ↗, LDA ↗, representaciones distribuidas o predictivas usando redes neuronales).
Para nuestro primer reto, extraer semántica, vamos a probar una representación continua llamada representación distribuida de palabras (distributed representations of words). Esta consiste en aprender representaciones vectoriales de palabras, es decir, vamos a tener un espacio multidimensional en el que una palabra es representada como un vector. Una de las cosas interesantes de estos vectores es que son capaces de extraer características tan relevantes como propiedades sintácticas y semánticas de las palabras (Turian et al, 2010 ↗). La otra es que este aprendizaje automático se realiza con datos de entrada no etiquetados, es decir, es no supervisado.
Estos vectores pueden ser utilizados como entrada de muchas aplicaciones de Procesamiento del Lenguaje Natural y Machine Learning. De hecho, es nuestro segundo reto utilizaremos estos vectores para intentar extraer temas de documentos.
Para aplicar esta técnica usamos la herramienta word2vec ↗ (Mikolov et al — Google, 2013 ↗), que utiliza como entrada un corpus de textos o documentos cualquiera, y obtener como salida vectores representando las palabras. La arquitectura en la que se basa word2vec utiliza redes neuronales para aprender estas representaciones. Aunque también se pueden obtener vectores que representen frases, párrafos o incluso documentos completos (Le and Mikolov, 2014 ↗).
A nivel de palabra#
Primero, utilizamos la implementación en Python de la herramienta word2vec, incluida en la librería gensim ↗. Como entrada para generar los vectores tenemos dos datasets con documentos en castellano: Wikipedia y Yahoo! Answers (de este dataset, solo los que están en español).
El proceso es el siguiente (Figura 1), dado el conjunto de textos, se construye un vocabulario y word2vec aprende las representaciones vectoriales de palabras. Los algoritmos de aprendizaje que utiliza word2vec son: bag-of-words continuo y skip-gram continuo ↗. Ambos algoritmos aprenden las representaciones de una palabra, las cuales son útiles para predecir otras palabras en la frase.
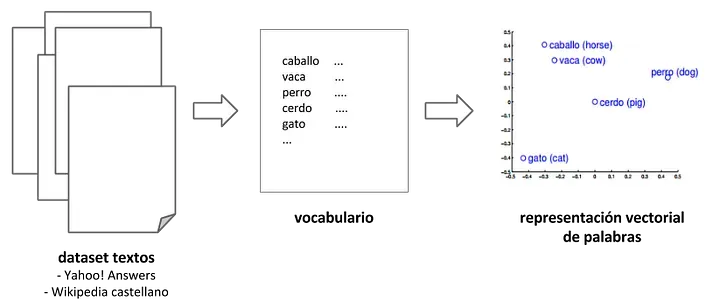 Creación de vectores de palabras
Creación de vectores de palabras
Como sabemos que los vectores capturan muchas regularidades lingüísticas, podemos aplicar operaciones vectoriales para extraer muchas propiedades interesantes. Por ejemplo, si queremos saber qué palabras son las más similares a una dada, buscamos cuales están más cerca aplicando ‘distancia coseno’ (cosine distance) o ‘similitud coseno’ (cosine similarity ↗).
Por ejemplo, con el modelo de Wikipedia, qué cinco palabras se parecen más a una dada.
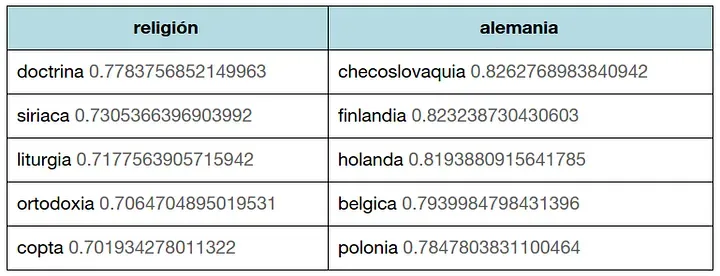 Con el modelo de Wikipedia, las cinco palabras más parecidas a religión y alemania.
Con el modelo de Wikipedia, las cinco palabras más parecidas a religión y alemania.
También podemos obtener qué seis palabras se parecen más a dos dadas con el modelo de la Wikipedia y el de Yahoo para ver las diferencias:
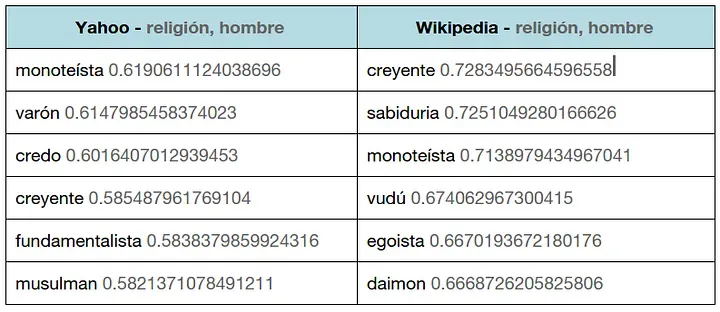 Comparando el modelo de Wikipedia y el de Yahoo, para las palabras religión y hombre.
Comparando el modelo de Wikipedia y el de Yahoo, para las palabras religión y hombre.
Otra propiedad interesante es que las operaciones vectoriales: vector(rey) — vector(hombre) + vector(mujer) nos da como resultado un vector muy cercano a vector(reina).
Por ejemplo, vector(pareja) — vector(hombre) + vector(novio) nos da como resultado estos vectores:
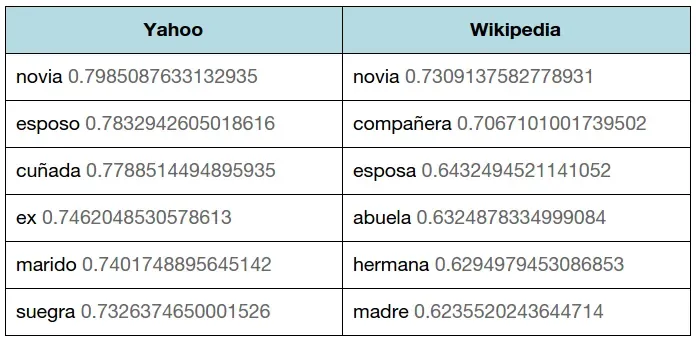 Comparando el modelo de Wikipedia y el de Yahoo, para la operación vectorial: vector(pareja) — vector(hombre) + vector(novio).
Comparando el modelo de Wikipedia y el de Yahoo, para la operación vectorial: vector(pareja) — vector(hombre) + vector(novio).
Al haber trabajado con dos conjuntos de datos diferentes, Wikipedia y Yahoo! answers, podemos crear dos espacios de representaciones vectoriales ligeramente diferentes con respecto al vocabulario usado y la semántica inherente en ellos. En el de Yahoo! encontramos entre las palabras más similares la misma palabra mal escrita de diferentes maneras. En wikipedia esto no pasa, pues la escritura es mucho más correcta.
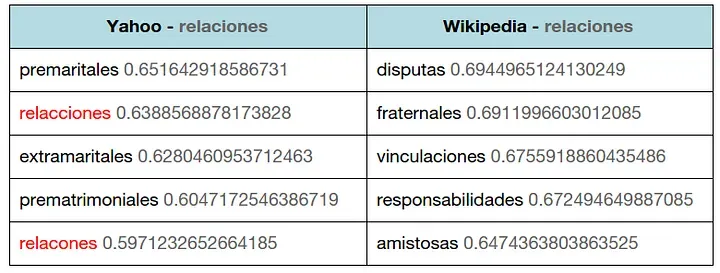 Comparando el modelo de Wikipedia y el de Yahoo, para la palabra relaciones.
Comparando el modelo de Wikipedia y el de Yahoo, para la palabra relaciones.
Además, en el conjunto de Yahoo! tenemos no sólo preguntas en castellano, sino que también encontramos otras en mejicano, argentino y otros dialectos de sudamérica. Esto nos permite encontrar palabras similares en diferentes dialectos.
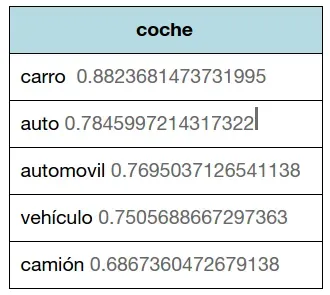 El vector coche en el modelo de Yahoo da palabras relacionadas en múltiples variedades del español.
El vector coche en el modelo de Yahoo da palabras relacionadas en múltiples variedades del español.
Con respecto al tiempo que tardamos en crear nuestro espacio de vectores, la mayoría del tiempo se dedica al preprocesamiento y limpieza de esos documentos. La implementación de gensim permite modificar los parámetros de creación del modelo e incluso utilizar varios workers con Cython ↗ para que el entrenamiento sea más rápido. La calidad de estos vectores dependerá de la cantidad de datos de entrenamiento, del tamaño de los vectores y del algoritmo elegido para entrenar. Para obtener mejores resultados, es necesario entrenar los modelos con datasets grandes y con suficiente dimensionalidad. Para más detalles os recomendamos la lectura del trabajo de Mikolov y Le ↗.
En la siguiente tabla os mostramos el tiempo que se tarda aproximadamente en entrenar unos 500 MB de datos, suficientes para obtener un buen modelo de vectores. El tiempo total es el tiempo que tardamos en preprocesar los datos, entrenar y guardar el modelo para posteriores usos.
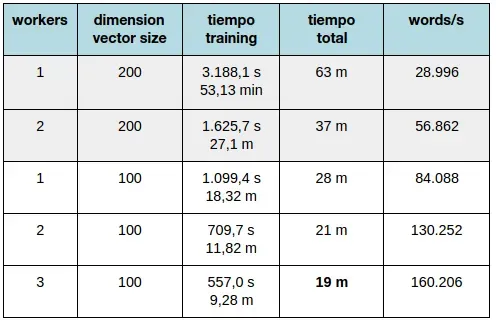 Tiempo de entrenamiento del modelo word2vec.
Tiempo de entrenamiento del modelo word2vec.
A nivel de documento#
Para usar a representaciones vectoriales de documentos hemos utilizado doc2vec ↗, también de gensim. Como entrada de datos, hemos considerado documento como una página de la wikipedia o una pregunta de yahoo con sus respuestas. Hemos variado el tamaño del fichero de entrada (de 100.000 documentos a 258.088) para un worker y una dimensión de 300 y el tiempo de entrenamiento se reduce bastante, lo podemos ver en la siguiente tabla:
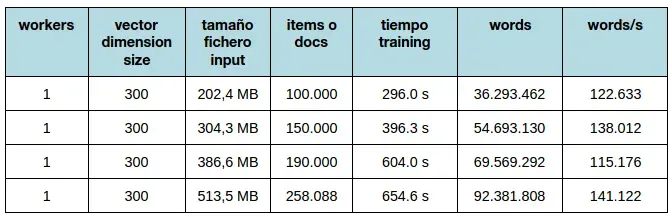 Tiempo de entrenamiento del modelo doc2vec.
Tiempo de entrenamiento del modelo doc2vec.
Los tests ejecutados para ver el comportamiento del espacio de vectores no han sido tan satisfactorios como con word2vec. Los resultados para palabras similares son peores que con word2vec y para encontrar documentos similares a uno dado, vemos que no devuelve nada con mucho sentido.
Como alternativa buscamos otros métodos que nos puedan decir qué documentos son parecidos entre sí. Os los presentaremos en el siguiente post.
Conclusiones y trabajo futuro#
Word2vec es considerado como un método inspirado en deep learning en ciertos grupos de especialistas en la materia y no tanto ‘deep learning’, sino ‘shallow learning’ en otros grupos ↗. Sea como sea, la creación de espacios vectoriales para extraer propiedades sintácticas y semánticas de las palabras, de manera automática y no supervisada, nos abre todo un mundo de posibilidades a explorar. Estos vectores sirven de entrada para muchas aplicaciones como traducción automática, clusterización, categorización, e incluso puede ser entrada de otros modelos basados en deep learning. Y es que además de aplicarse al lenguaje natural, se está aplicando también en imágenes y reconocimiento de voz ↗.
Ya que doc2vec no nos ha gustado mucho, nuestro siguiente paso es aplicar estos espacios vectoriales a extraer temas y categorías de documentos con técnicas habituales en el mundo del Procesamiento del Lenguaje Natural y de Machine Learning como tf-idf. ↗ De ello hablaremos en un siguiente post “Conceptos en la extracción automática de información de documentos”.
Lee aquí el post “Conceptos en la extracción automática de información”.
Agradecimientos#
El corpus de datos de Yahoo (L6 — Yahoo! Answers Comprehensive Questions and Answers version 1.0 (multi part)) ha sido obtenido gracias a Yahoo! Webscope ↗. Para procesar estos datos hemos utilizado la librería gensim ↗ para Python que implementa word2vec ↗.
Fuente imagen principal: freedigitalphotos.net / kangshutters
Originally published at labs.beeva.com on February 2, 2015. BEEVA is now BBVA Technology.